前言
什么是 PaddleOCR
根据官方的介绍:
Awesome multilingual OCR toolkits based on PaddlePaddle (practical ultra lightweight OCR system, support 80+ languages recognition, provide data annotation and synthesis tools, support training and deployment among server, mobile, embedded and IoT devices)
PaddleOCR 是一个基于百度飞桨(Paddle)平台部署的 OCR 工具库,支持多设备、多平台、多语言、多场景的 OCR 识别。
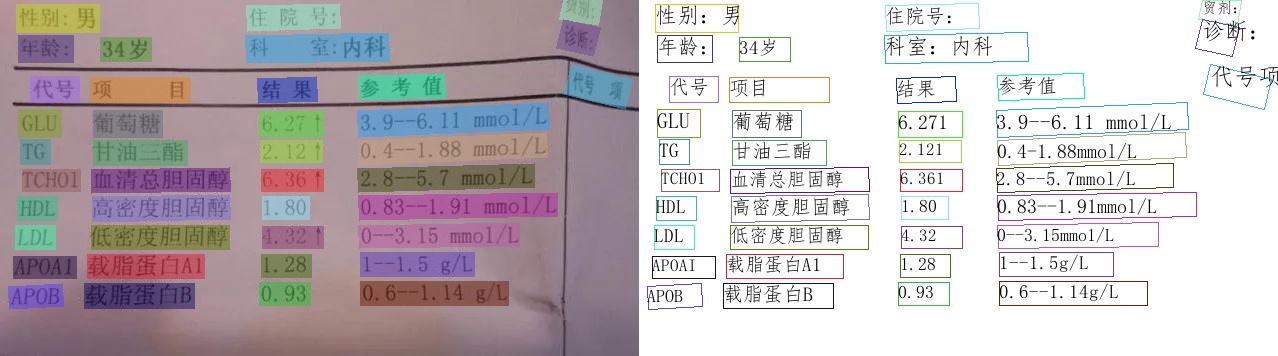
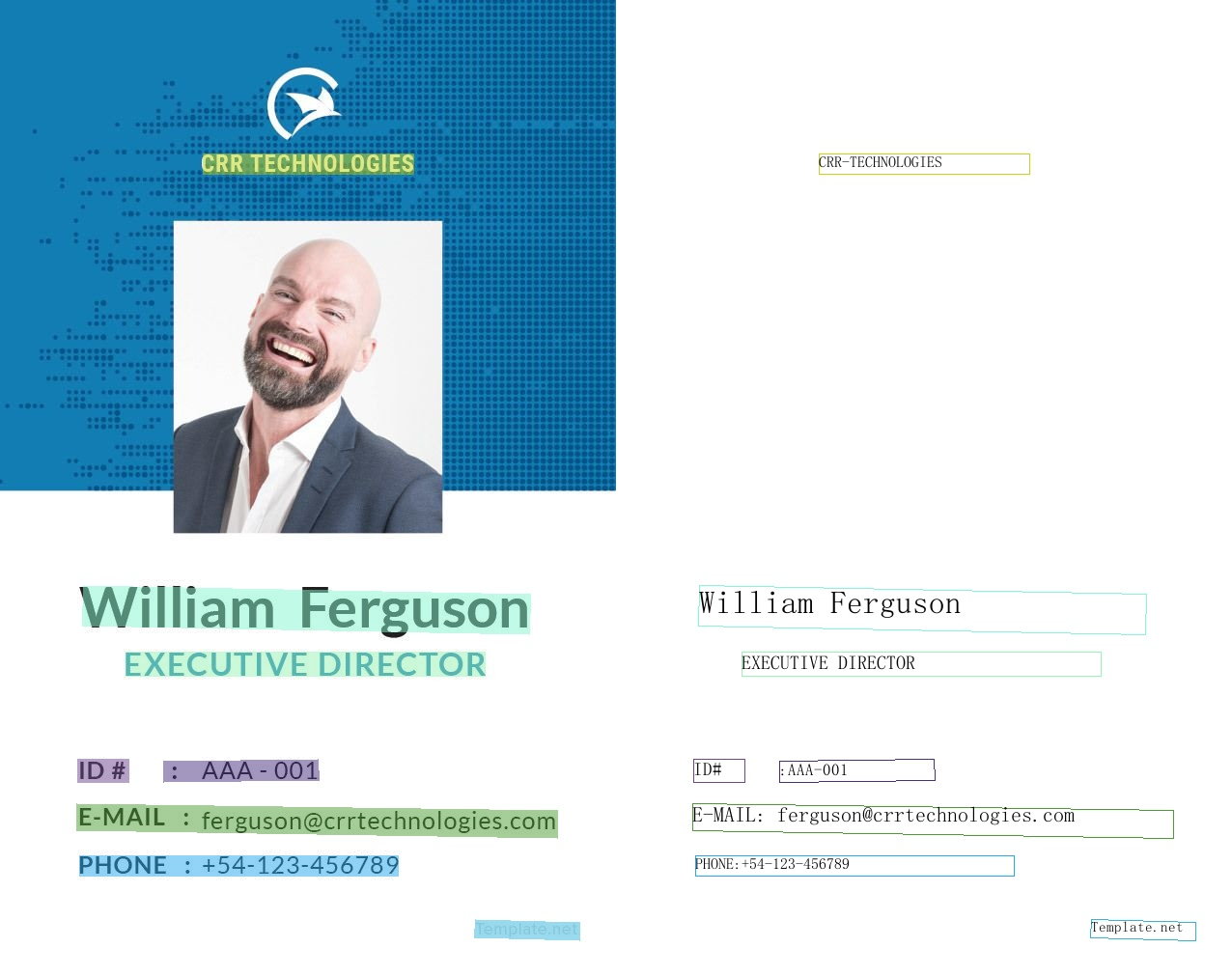
这里是一些官方的识别效果示例图:
来源:PaddleOCR


为什么要二次封装
虽然 PaddleOCR 十分强大,但是部署使用较为繁琐,对于新手或者说不关心 PaddleOCR 实现,也不需要太多自定义参数的使用者来说十分不方便。
对于部分使用者来说,他们想要的只是一个能够快速接入安卓项目使用的离线 OCR 识别库而已。
因此,本文的目的就是想要将 PaddleOCR 二次封装为能够快速接入使用的安卓库。
该库将基于官方的 android_demo 进行封装。
怎么使用
封装完成后使用极其简单,在导入依赖后,只需要两行代码即可使用:
ocr.initModelSync(OcrConfig()) // 初始化 OCR
val result = ocr.runSync(yourBitmap) // 开始识别
更多配置和详细使用流程请前往项目地址查看。
项目地址
欢迎 star
效果预览:

封装思路
分析官方 android_demo
在开始封装之前,我们需要大致了解 android_demo 的运行逻辑。
在 demo 中的 build.gradle 中有这么一段代码:
def archives = [
[
'src' : 'https://paddleocr.bj.bcebos.com/libs/paddle_lite_libs_v2_10.tar.gz',
'dest': 'PaddleLite'
],
[
'src' : 'https://paddlelite-demo.bj.bcebos.com/libs/android/opencv-4.2.0-android-sdk.tar.gz',
'dest': 'OpenCV'
],
[
'src' : 'https://paddleocr.bj.bcebos.com/PP-OCRv2/lite/ch_PP-OCRv2.tar.gz',
'dest' : 'src/main/assets/models'
],
[
'src' : 'https://paddleocr.bj.bcebos.com/dygraph_v2.0/lite/ch_dict.tar.gz',
'dest' : 'src/main/assets/labels'
]
]
task downloadAndExtractArchives(type: DefaultTask) {
doFirst {
println "Downloading and extracting archives including libs and models"
}
doLast {
// Prepare cache folder for archives
String cachePath = "cache"
if (!file("${cachePath}").exists()) {
mkdir "${cachePath}"
}
archives.eachWithIndex { archive, index ->
MessageDigest messageDigest = MessageDigest.getInstance('MD5')
messageDigest.update(archive.src.bytes)
String cacheName = new BigInteger(1, messageDigest.digest()).toString(32)
// Download the target archive if not exists
boolean copyFiles = !file("${archive.dest}").exists()
if (!file("${cachePath}/${cacheName}.tar.gz").exists()) {
ant.get(src: archive.src, dest: file("${cachePath}/${cacheName}.tar.gz"))
copyFiles = true; // force to copy files from the latest archive files
}
// Extract the target archive if its dest path does not exists
if (copyFiles) {
copy {
from tarTree("${cachePath}/${cacheName}.tar.gz")
into "${archive.dest}"
}
}
}
}
}
preBuild.dependsOn downloadAndExtractArchives
这段代码的作用很好理解,就是在每次编译前先检查文件,如果不存在则从指定地址下载 paddle_lite_libs 、 opencv 、 模型(ch_PP-OCRv2) 、 字典(ch_dict) 并解压后复制到指定文件夹。
官方这么做的原因无非是为了减少仓库的体积,但是我们封装时不太需要考虑仓库体积问题,所以我们直接将下载好的所需依赖文件复制到项目中,并去除这段下载代码。
继续查看 demo 中的主入口 - MainActivity 文件,这个文件写的比较复杂繁琐,不过没关系,我们挑重点的看。
首先是这段代码:
@Override
protected void onResume() {
super.onResume();
// ......
if (model_settingsChanged) {
// ......
// Reload model if configure has been changed
loadModel();
}
}
这段代码会在 onResume 时检查参数设置是否改变,如果改变的话则加载模型:
loadModel() 方法发送了一个 Handler message , 接收到 message 后做的处理为:
if (predictor.isLoaded()) {
predictor.releaseModel();
}
return predictor.init(MainActivity.this, modelPath, labelPath, cbOpencl.isChecked() ? 1 : 0, cpuThreadNum,
cpuPowerMode,
detLongSize, scoreThreshold);
代码很简单,检查是否已经加载了模型,如果已加载就重新加载一次,否则就初始化。
再来看看识别时都做了什么,点击 开始识别 后最终会调用到这段代码:
String run_mode = spRunMode.getSelectedItem().toString();
int run_det = run_mode.contains("检测") ? 1 : 0;
int run_cls = run_mode.contains("分类") ? 1 : 0;
int run_rec = run_mode.contains("识别") ? 1 : 0;
return predictor.isLoaded() && predictor.runModel(run_det, run_cls, run_rec);
代码也很简单,从下拉框中获取识别的类型,然后将识别类型传入 predictor.runModel 并返回识别结果(是否识别成功)。
从上面的代码中可以看出来,这个代码的核心在于 Predictor 类:Predictor predictor = new Predictor();
我们来看一下 Predictor 类都做了些什么,其他的都不看了,我们就看一下 加载模型(init) 和 开始识别(runModel)。
首先是 init 方法:
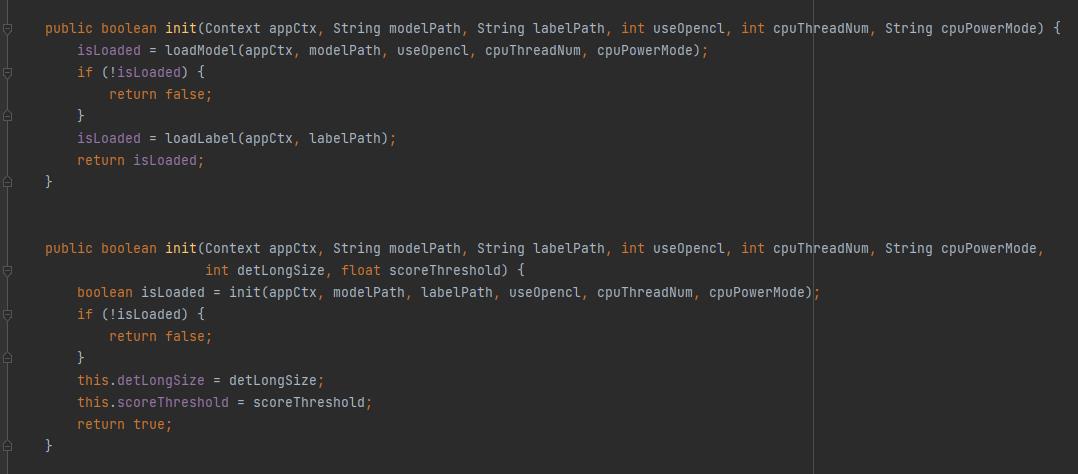
可以看到 init 有两个构造方法,第二个构造方法比第一个多了两个参数: detLongSize - 检测长度; scoreThreshold - 置信度阈值。
在 init 中所做的事无非是按照给定的参数加载模型(Model)和字典(Label)。
这里说一下,paddleOCR 返回的识别结果不是字符,而是一串字符索引,我们需要根据字典将索引转换为具体的字符。
下面为 loadModel 方法的具体实现:
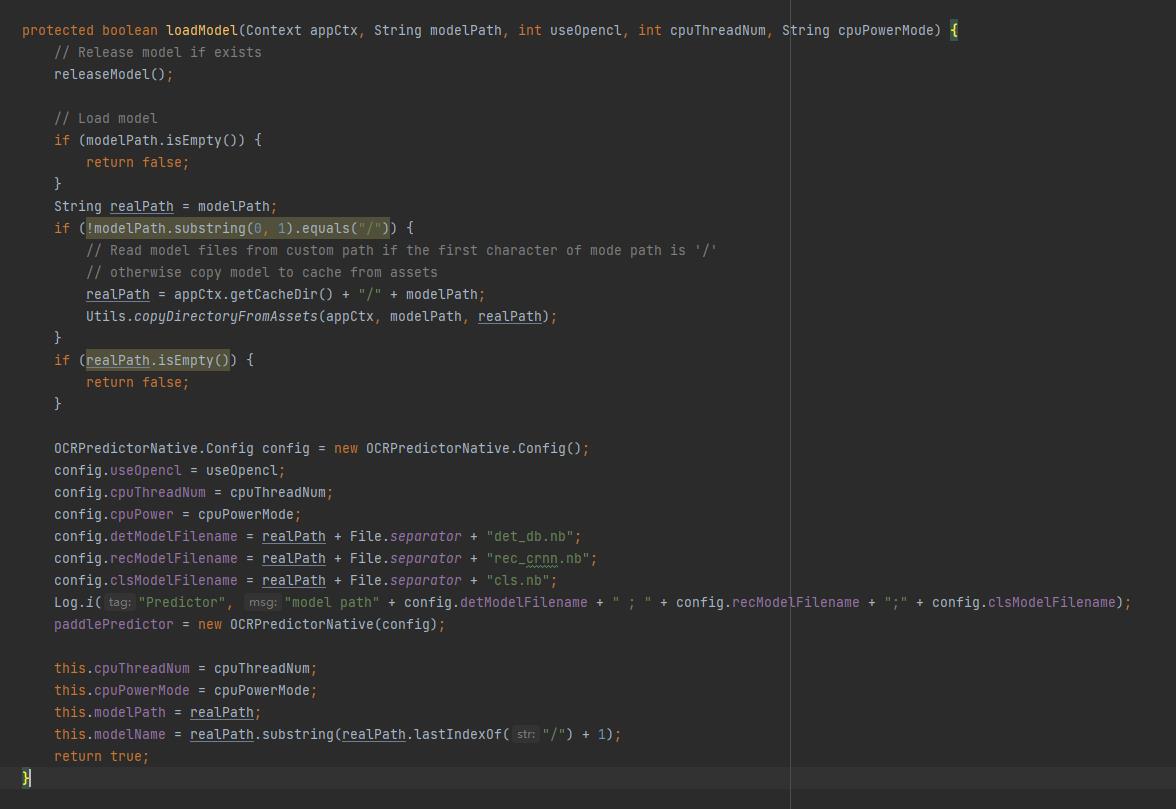
在 loadModel 方法中,会先检查传入的模型路径是否为 / 开头,如果不是斜杆开头则认为是传入的 assets 路径(即模型文件打包进了安装包),此时需要将模型复制到内部储存中(copyDirectoryFromAssets),然后将模型路径以及其他参数写入配置信息(config)。
加载字典代码如下:
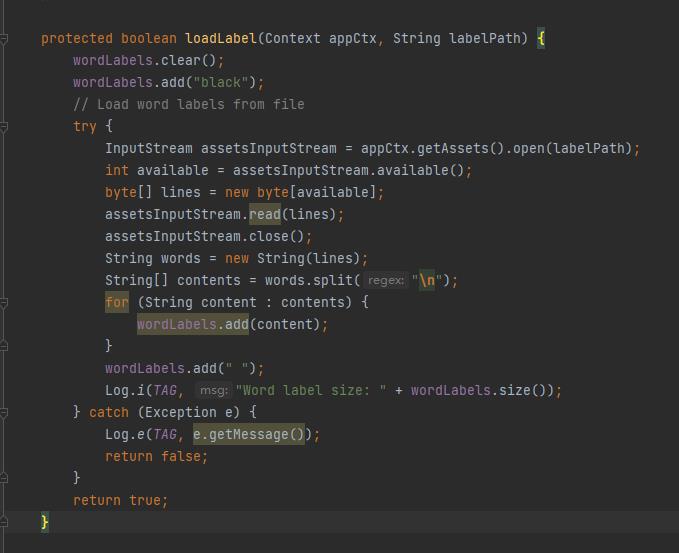
在加载字典时,会读取给定的字典文件,并按行分割后将其写入一个列表中(wordLabels)以备后用。
wordLabels 列表的第一个值被恒定写入为 “black” ,这是因为识别失败时会返回索引 0 。
需要注意的是,这里没有对字典文件路径做判断,而是直接将字典文件看作保存在 assets 文件夹中。
最后来看一下开始识别的代码:
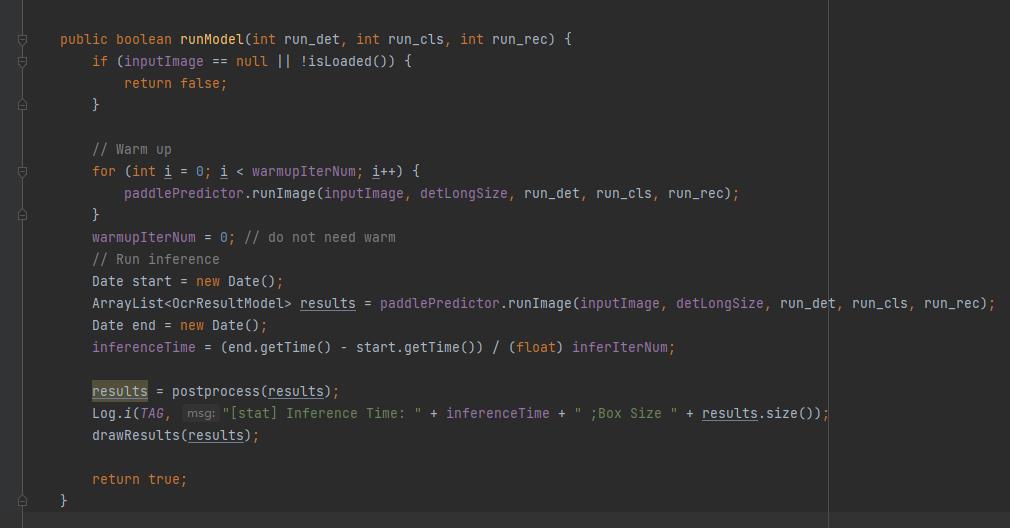
在这段代码中,首先判断如果输入图像为空或尚未加载模型则直接返回 false 。
然后对输入图像进行 “预热”。
“预热” 完成后调用 paddlePredictor.runImage 开始识别。
最后,使用 postprocess 对识别结果进行后处理,这里的后处理就是上文提到的,将文字索引按照字典转换为字符,所以这里就不再看源码了。
最后,看看最核心的 runImage 方法:
// ....
public ArrayList<OcrResultModel> runImage(Bitmap originalImage, int max_size_len, int run_det, int run_cls, int run_rec) {
Log.i("OCRPredictorNative", "begin to run image ");
float[] rawResults = forward(nativePointer, originalImage, max_size_len, run_det, run_cls, run_rec);
ArrayList<OcrResultModel> results = postprocess(rawResults);
return results;
}
// ....
protected native float[] forward(long pointer, Bitmap originalImage,int max_size_len, int run_det, int run_cls, int run_rec);
// ......
可以看到,最终 runImage 方法是调用了 native 方法 forward。
其实不只是识别模型,包括上面说的加载模型等,最终都是调用的 native 方法。
也就是说,我们需要连 C++ 代码一起修改。
开始封装
上面我们已经把 demo 的运行逻辑捋了一遍,下面就是开始封装。
复制并修改文件
首先,我们需要创建一个 Android Library,创建过程在这里不过多赘述,只是需要说一点,我们的包名设置为 com.equationl.paddleocr4android 。
为什么要特意强调包名呢?因为在上面我们说过,paddleOCR 最终调用的是 native 方法,而通过 jni 调用 native 方法时,需要确保方法签名与调用者的包名一致。
我们将 demo 中的所有帮助类复制进我们的 Library ,并修改包名,解决报红的地方:
然后将所有 C/C++ 代码以及上面通过 build.gradle 下载的第三方依赖代码复制到指定位置:
最后,记得修改所有调用的 C++ 代码的方法签名,例如,将原本的 init 函数
Java_com_baidu_paddle_lite_demo_ocr_OCRPredictorNative_init
修改为
Java_com_equationl_paddleocr4android_Util_paddle_OCRPredictorNative_init
二次封装调用代码
首先,我们写一个数据类 OcrConfig 用于存放配置信息,避免按照原 demo 的写法每个方法都需要传一大堆参数:
data class OcrConfig(
/**
* 模型路径(默认为 assets 目录下的预装模型)
*
* 如果该值以 "/" 开头则认为是自定义路径,程序会直接从该路径加载模型;
* 否则认为该路径传入的是 assets 下的文件,则将其复制到 cache 目录下后加载
*
* */
var modelPath:String = "models/ocr_v2_for_cpu",
/**
* label 词组列表路径(程序返回的识别结果是该词组列表的索引)
* */
var labelPath: String? = "labels/ppocr_keys_v1.txt",
/**
* 使用的CPU线程数
* */
var cpuThreadNum: Int = 4,
/**
* cpu power model
* */
var cpuPowerMode: CpuPowerMode = CpuPowerMode.LITE_POWER_HIGH,
/**
* Score Threshold
* */
var scoreThreshold: Float = 0.1f,
var detLongSize: Int = 960,
/**
* 检测模型文件名
* */
var detModelFilename: String = "ch_ppocr_mobile_v2.0_det_opt.nb",
/**
* 识别模型文件名
* */
var recModelFilename: String = "ch_ppocr_mobile_v2.0_rec_opt.nb",
/**
* 分类模型文件名
* */
var clsModelFilename: String = "ch_ppocr_mobile_v2.0_cls_opt.nb",
/**
* 是否运行检测模型
* */
var isRunDet: Boolean = true,
/**
* 是否运行分类模型
* */
var isRunCls: Boolean = true,
/**
* 是否运行识别模型
* */
var isRunRec: Boolean = true,
var isUseOpencl: Boolean = false,
/**
* 是否绘制文字位置
*
* 如果为 true, [OcrResult.imgWithBox] 返回的是在输入 Bitmap 上绘制出文本位置框的 Bitmap
*
* 否则,[OcrResult.imgWithBox] 将会直接返回输入 Bitmap
* */
var isDrwwTextPositionBox: Boolean = false
)
enum class CpuPowerMode {
/**
* HIGH(only big cores)
* */
LITE_POWER_HIGH,
/**
* LOW(only LITTLE cores)
* */
LITE_POWER_LOW,
/**
* FULL(all cores)
* */
LITE_POWER_FULL,
/**
* NO_BIND(depends on system)
* */
LITE_POWER_NO_BIND,
/**
* RAND_HIGH
* */
LITE_POWER_RAND_HIGH,
/**
* RAND_LOW
* */
LITE_POWER_RAND_LOW
}
然后重新编写一个结果类,用于存放识别结果,原 demo 的识别结果有点混乱,不方便使用:
data class OcrResult(
/**
* 简单识别结果
* */
val simpleText: String,
/**
* 识别耗时
* */
val inferenceTime: Float,
/**
* 框选出文字位置的图像
* */
val imgWithBox: Bitmap,
/**
* 原始识别结果
* */
val outputRawResult: ArrayList<OcrResultModel>,
)
最后,编写入口类 OCR , 它的方法结构如下:
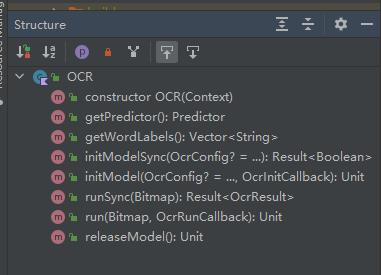
核心方法就四个:
initModelSync- 同步初始化识别引擎initModel- 异步初始化引擎runSync- 同步识别run- 异步识别
其中,两个异步方法其实就是在同步方法上套了一个协程,并用回调函数返回结果,例如异步识别:
/**
* 开始运行识别模型(异步)
*
* @param bitmap 欲识别的图片
* @param callback 识别结果回调
* */
@MainThread
fun run(bitmap: Bitmap, callback: OcrRunCallback) {
val coroutineScope = CoroutineScope(Dispatchers.IO)
coroutineScope.launch(Dispatchers.IO) {
runSync(bitmap).fold(
{
withCopntext(Dispatchers.Main) {
callback.onSuccess(it)
}
},
{
withCopntext(Dispatchers.Main) {
callback.onFail(it)
}
})
}
}
而同步方法的实现如下:
/**
* 开始运行识别模型(同步)
*
* @param bitmap 欲识别的图片
* */
@WorkerThread
fun runSync(bitmap: Bitmap): Result<OcrResult> {
if (!predictor.isLoaded()) {
return Result.failure(RunModelException("请先加载模型!"))
}
else {
predictor.setInputImage(bitmap) // 载入图片
runModel().fold({
return if (it) {
val ocrResult = OcrResult(
predictor.outputResult(),
predictor.inferenceTime(),
predictor.outputImage(),
predictor.outputRawResult()
)
Result.success(ocrResult)
} else {
Result.failure(RunModelException("请检查模型是否已成功加载!"))
}
}, {
return Result.failure(it)
})
}
}
最终调用的还是原 demo 中的 setInputImage() 和 runModel() 方法,然后原 demo 最终会调用到 native 方法。
只不过这里,我对识别结果进行了二次处理,将其处理完成后存入上面定义的 OcrResult 中。
并且,这里的同步方法返回的是一个 Result 类型,包裹的内容是 OcrResult 类型。
为了适配这个返回类型,我把原 demo 中的所有方法返回值均去掉了,并且在出错的地方直接改成抛出异常,并在这里 catch 住异常,并返回 Result.failure() :
private fun runModel(): Result<Boolean> {
return try {
Result.success(predictor.isLoaded() && predictor.runModel(isRunDet, isRunCls, isRunRec))
} catch (e: Throwable) {
Result.failure(e)
}
}
最后,就是修改原 demo 的几个帮助类,使其能够适配我二次封装的需求即可。
至此,所有封装全部完成!
总结
其实 PaddleOCR 部署并不算复杂,只是由于它的多平台特性,导致新手使用时会看的一脸懵逼,不知道到底该怎么去使用。
最后,这个库我已经在我自己的项目 隐云图解制作 中使用了半年多了,目前没有发现有什么大问题,所以各位可以大胆的去尝试使用。
当然,这个库只是为了方便快速接入使用 OCR 的开发者,如果你想要更多的自定义或扩展功能,还是得你自己去研究部署 PaddleOCR,如果你恰好有时间,并且认为这些功能其他人也能用的到的话,欢迎 PR 到这个库中。