前言
在上一篇文章(基于 jetpack compose,使用MVI架构+自定义布局实现的康威生命游戏),我们讲了如何使用 compose 实现一个康威生命游戏,虽然我说运行很流畅,但是实际上如果画布尺寸稍微设置大一点就会出现卡顿,本文就将探究卡顿的原因,并给出优化方案,并且最终将计算时间由 20+ms 优化至 3ms。
提示:为了方便说明问题,下面的速度测试均是在一个超级低端机(RK3288处理器,2GB DDR3运行内存)上进行的,所以耗时是正常手机的数十倍,例如,该低端设备在优化前耗时 20+ms,但是在正常手机上耗时只有个位数。
开始优化
优化前速度
开始之前我们先来测试一下目前计算一个 100x100 的格子一轮需要耗时多久,在步进更新代码处(runStep)添加如下代码:
val startTime = System.currentTimeMillis()
val newList = viewStates.playGroundState.stepUpdate()
Log.i(TAG, "runStep: step duration: ${System.currentTimeMillis() - startTime} ms")
编译运行,输出如下:
runStep: step duration: 24 ms
runStep: step duration: 23 ms
runStep: step duration: 25 ms
runStep: step duration: 23 ms
runStep: step duration: 24 ms
runStep: step duration: 23 ms
runStep: step duration: 27 ms
runStep: step duration: 26 ms
runStep: step duration: 24 ms
runStep: step duration: 23 ms
runStep: step duration: 24 ms
runStep: step duration: 23 ms
runStep: step duration: 22 ms
runStep: step duration: 24 ms
runStep: step duration: 22 ms
runStep: step duration: 23 ms
runStep: step duration: 24 ms
可以看到,更新一轮大约需要 20-25 ms,这还仅仅只是计算新的状态,不包括绘制的时间,如果再加上绘制时间,这个耗时将变得难以接受。
查看耗时方法
打开 AndroidStudio 的 ProFiler 录制进程信息,查看单次步进计算时都是哪些方法“拖了后腿”:
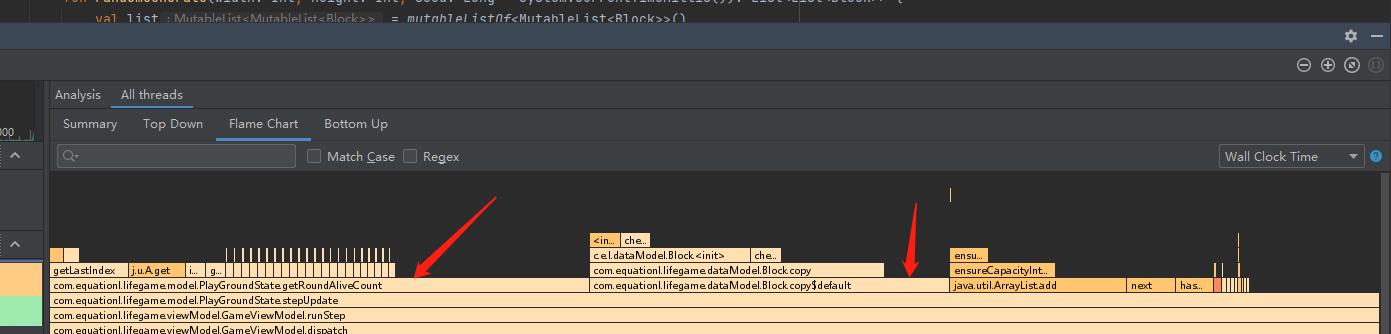
可以看出,耗时方法主要是 getRoundAliveCount 和 copy 。很好!找到元凶了……吗?
其实不然,这只是假象,真正耗时的其实并不是他俩,不明白?我们再来回顾一下他俩出现的地方:

发现了吗?没错,它俩都是在循环当中。
也就是说,虽然它俩确实比较耗时,但是也没有离谱到会被计算速度拉低到几十 ms 的地步,罪魁祸首是因为他们在循环之中,于是他们的耗时随着循环次数增加也在被不断的累积。
那么,应该怎么去优化呢?
首先看看 getRoundAliveCount 放大这个方法的耗时情况,可以看到它的耗时大多数是被取各种属性累计起来了:

这个咱们确实可以优化,比如,对于 lastIndex 属性,这个值是固定不变的,不用每次遍历都去取一次, 还有 ArrayList.get() 其实这个方法有很多重复调用的地方,也可以优化一下,用空间换时间。而对于其他的耗时,诸如 Block.isAlive 、 Block.State 这个无法更改。
那么我们再来看看 copy 是什么情况,这个都不用看图了,一想就知道,每次遍历 copy 时都会创建一个新的 Block 对象,耗时自然会居高不下。
通过减少对象创建和重复调用方法优化速度
那么应该怎么优化呢?
还记得我们前面说过的吗?细胞的状态有且仅有存活和死亡两种情况,也就是说,这里用 data class 嵌套 enum class 实属多余,只会徒增运行成本,此处其实可以直接使用 Int 或 Boolean 这种基本数据类型来储存。
这样做还有一个好处,那就是上面说到的取 Block 属性的耗时也可以同样的优化掉。
再更改一下判断条件,尽可能的减少判断次数,并且按照上面思路减少对象的创建,修改后代码如下:
/**
* 更新一步状态
* */
fun stepUpdate(): MutableList<MutableList<Int>> {
// 深度复制,不然无法 recompose
val newLifeList: MutableList<MutableList<Int>> = mutableListOf()
lifeList.forEach { lineList ->
newLifeList.add(lineList.map { it }.toMutableList())
}
val columnLastIndex = newLifeList.size - 1
val rowLastIndex = newLifeList[0].size - 1
newLifeList.forEachIndexed { columnIndex, lineList ->
lineList.forEachIndexed { rowIndex, block ->
val aroundAliveCount = getRoundAliveCount(rowIndex, columnIndex, columnLastIndex, rowLastIndex)
if (block.isAlive()) { // 当前细胞存活
if (aroundAliveCount < 2) newLifeList[columnIndex][rowIndex] = Block.DEAD
if (aroundAliveCount > 3) newLifeList[columnIndex][rowIndex] = Block.DEAD
}
else { // 当前细胞死亡
if (aroundAliveCount == 3) newLifeList[columnIndex][rowIndex] = Block.ALIVE
}
}
}
return newLifeList
}
private fun getRoundAliveCount(posX: Int, posY: Int, columnLastIndex: Int, rowLastIndex: Int): Int {
var count = 0
// 将当前细胞周围细胞按照下面序号编号
// y y y
// x 0 1 2
// x 3 pos 4
// x 5 6 7
if (posY > 0) {
val topLine = lifeList[posY-1]
// 查找 0 号
if (posX > 0 && topLine[posX-1].isAlive()) count++
// 查找 1 号
if (topLine[posX].isAlive()) count++
// 查找 2 号
if (posX < rowLastIndex && topLine[posX+1].isAlive()) count++
}
if (posY < columnLastIndex) {
val bottomLine = lifeList[posY+1]
// 查找 5 号
if (posX > 0 && bottomLine[posX-1].isAlive()) count++
// 查找 6 号
if ( bottomLine[posX].isAlive()) count++
// 查找 7 号
if (posX < rowLastIndex && bottomLine[posX+1].isAlive()) count++
}
val currentLine = lifeList[posY]
// 查找 3 号
if (posX > 0 && currentLine[posX-1].isAlive()) count++
// 查找 4 号
if (posX < rowLastIndex && currentLine[posX+1].isAlive()) count++
return count
}
上面定义了两个常量和一个扩展函数:
const val DEAD = 0
const val ALIVE = 1
fun Int.isAlive() = this == ALIVE
同样运行 100x100 的格子耗时如下:
step duration: 10 ms
step duration: 9 ms
step duration: 9 ms
step duration: 9 ms
step duration: 10 ms
step duration: 9 ms
step duration: 9 ms
step duration: 10 ms
step duration: 10 ms
step duration: 9 ms
step duration: 9 ms
step duration: 9 ms
step duration: 9 ms
step duration: 9 ms
step duration: 10 ms
step duration: 9 ms
step duration: 9 ms
耗时成功被控制在了 10ms 左右!
通过移除冗余的拷贝数组优化速度
但是还是觉得不太满意,那么怎么办呢?之所以这么耗时是因为这段代码遍历了两次,一次用来复制数组,一次用来计算,总觉得复制数组这段时间好浪费啊,能不能干掉呢?
欸,还真的能,还记得吗?我们之所以要深度复制数组,一来是因为不复制无法触发 recompose ,二来是因为如果直接改原数组会造成计算错误。
由于我们现在已经把数组储存数据从对象改成了基本数据类型,所以不存在无法 recompose 的情况了。
那么,第二条怎么解决呢?也很简单,我们不是把数据类型改为了 Int 嘛?
0 表示死亡;1 表示存活,那我们再多加几个状态不就得了?用 3 表示 从存活变成死亡,4 表示从死亡复活。
然后在下一轮计算时顺手改回 0 或者 1,不就行了?
说干就干,增加两个状态:
const val ALIVE_TO_DEAD = 3
const val DEAD_TO_ALIVE = 4
fun Int.isAlive() = (this == ALIVE || ALIVE_TO_DEAD)
然后去掉复制数组的代码,直接操作原数组。
看一下耗时,因为其实复制数组耗时非常小,所以改成 500x500 的格子来测试,这是去掉复制数组前的耗时:
runStep: step duration: 471 ms
runStep: step duration: 432 ms
runStep: step duration: 447 ms
runStep: step duration: 432 ms
runStep: step duration: 428 ms
runStep: step duration: 426 ms
runStep: step duration: 435 ms
runStep: step duration: 436 ms
runStep: step duration: 438 ms
runStep: step duration: 424 ms
runStep: step duration: 436 ms
runStep: step duration: 427 ms
runStep: step duration: 434 ms
这是去除复制后的耗时:
runStep: step duration: 528 ms
runStep: step duration: 531 ms
runStep: step duration: 521 ms
runStep: step duration: 522 ms
runStep: step duration: 521 ms
runStep: step duration: 521 ms
runStep: step duration: 524 ms
runStep: step duration: 520 ms
runStep: step duration: 518 ms
runStep: step duration: 518 ms
runStep: step duration: 517 ms
runStep: step duration: 517 ms
runStep: step duration: 522 ms
runStep: step duration: 521 ms
runStep: step duration: 520 ms
runStep: step duration: 515 ms
怎么回事???反而耗时更大了?
显然,由于增加了额外的两个状态,在设置和读取状态时的耗时远远超过了直接复制数组的耗时,得不偿失,还是继续老老实实复制吧。
这里已经无法优化了,但是还是觉得这个耗时无法接受怎么办?有没有办法让速度更快一点?
看来看去,最终的着手点似乎都落在了减少遍历次数上,可是减少遍历次数说着简单,真实践起来太困难了,以我的技术水平目前无法做到……
那怎么办呢?
使用NDK优化速度
在B大佬的提醒下,我恍然大悟,或许可以使用 C/C++ 来实现这部分的计算,众所周知 C/C++ 的运行速度可比 Jvm 快多了。
安卓怎么使用 NDK 这些我就不再赘述了,不清楚的可以搜一搜,我在这里就直接写了。
对了,测试的时候发现一个坑爹的地方,
从 C++ 中获取 kotlin 的 数组时需要使用 GetIntArrayElements 函数。
但是我写好后报错:
JNI DETECTED ERROR IN APPLICATION: incompatible array type java.lang.Integer[] expected int[]: 0x20001d in call to GetIntArrayElements
from java.lang.Integer[][] com.equationl.lifegamenative.LifeGameNativeLib.stepUpdate(java.lang.Integer[][])
嗯?我的 kt 代码是这样写的:
external fun stepUpdate(lifeList: Array<Array<Int>>): Array<Array<Int>>
什么情况?难道是 kt 中的 Int 编译到 jvm 会转成 Integer ? 查看 kt 代码转成字节码后反编译代码:
@NotNull
public final native Integer[][] stepUpdate(@NotNull Integer[][] var1);
啊这?还真是……
多次实验之后,发现使用 IntArray 就能被编译成 int[] 而不是 Integer[] 。 那就问题不大了,随便改一下其它地方的数据类型。
解决了上面这个坑爹的问题,我们来看看怎么改用C++来计算细胞状态。
首先,由于直接使用从 java 传过来的 array 非常麻烦,还得调 java 的方法,所以将从 java 中拿到的 array 转为 c++ 的数据格式:
int len1 = env -> GetArrayLength(lifeList);
auto dim = (jintArray)env->GetObjectArrayElement(lifeList, 0);
int len2 = env -> GetArrayLength(dim);
int **board;
board = new int *[len1];
for(int i=0; i<len1; ++i){
auto oneDim = (jintArray)env->GetObjectArrayElement(lifeList, i);
jint *element = env->GetIntArrayElements(oneDim, JNI_FALSE);
env->ReleaseIntArrayElements(oneDim, element, JNI_ABORT);
env->DeleteLocalRef(oneDim);
board[i] = new int [len2];
for(int j=0; j<len2; ++j) {
board[i][j]= element[j];
}
}
lifeList 即 java 传过来的二维数组,上述代码很简单,就是通过调用 java 的方法 GetArrayLength 获取到 lifeList 的长度后创建一个 int **board (可以理解为二维数组),然后将 lifeList 中的数据拷贝到 board 中。
其中,ReleaseIntArrayElements 和 DeleteLocalRef 都是用来释放对 lifeList 的引用,避免内存泄漏。
有了数据,下一步就是计算新的细胞存活状态,由于我对 C++ 不是太熟悉,虽然自己也按照 java 算法写了一套,但是总觉得不够优雅,所以我去力扣摘抄了一份我觉得很优雅的算法过来:
/*
* 该算法来源如下:
*
* 作者:Time-Limit
* 链接:https://leetcode.cn/problems/game-of-life/solution/c-wei-yun-suan-yuan-di-cao-zuo-ji-bai-shuang-bai-b/
* 来源:力扣(LeetCode)
* 著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
*/
int dx[] = {-1, 0, 1, -1, 1, -1, 0, 1};
int dy[] = {-1, -1, -1, 0, 0, 1, 1, 1};
for(int i = 0; i < len1; i++) {
for(int j = 0 ; j < len2; j++) {
int sum = 0;
for(int k = 0; k < 8; k++) {
int nx = i + dx[k];
int ny = j + dy[k];
if(nx >= 0 && nx < len1 && ny >= 0 && ny < len2) {
sum += (board[nx][ny]&1); // 只累加最低位
}
}
if(board[i][j] == 1) {
if(sum == 2 || sum == 3) {
board[i][j] |= 2; // 使用第二个bit标记是否存活
}
} else {
if(sum == 3) {
board[i][j] |= 2; // 使用第二个bit标记是否存活
}
}
}
}
for(int i = 0; i < len1; i++) {
for(int j = 0; j < len2 ; j++) {
board[i][j] >>= 1; //右移一位,用第二bit覆盖第一个bit。
}
}
好的,有了算法,下一步当然是把 c++ 的数据转回到 java 的数据:
jclass cls = env->FindClass("[I");
jintArray iniVal = env->NewIntArray(len2);
jobjectArray result = env->NewObjectArray(len1, cls, iniVal);
for (int i = 0; i < len1; i++)
{
jintArray inner = env->NewIntArray(len2);
env->SetIntArrayRegion(inner, 0, len2, board[i]);
env->SetObjectArrayElement(result, i, inner);
env->DeleteLocalRef(inner);
}
c++ 转 java 和上面 java 转 c++ 流程大差不差,我这里就不过多赘述了。
提示:因为 NDK 使用的是 JNI 调用 C/C++ 方法,所以其实与其说是 kotlin 与 c++ 交互,不如说是 java,上面为了顺口,我全部写成了 java,实际使用的是 kotlin 。
调用 C++ 代码的 kotlin 类:
class LifeGameNativeLib {
external fun stepUpdate(lifeList: Array<IntArray>): Array<IntArray>
companion object {
init {
System.loadLibrary("lifegamenative")
}
}
}
最后一步,更改 stepUpdate 方法,因为需要加载 .so 文件,所以我新建了一个 PlayGroundUtils 单例类来处理:
object PlayGroundUtils {
private var lifeGameNativeLib: LifeGameNativeLib = LifeGameNativeLib()
fun stepUpdate(sourceData: Array<IntArray>): Array<IntArray> {
return lifeGameNativeLib.stepUpdate(sourceData)
}
}
相应的数据类型也需要更改,我这里就不过多赘述了。
这下就完全搞定了,下面就是运行,同样的 100x100 格子,让我们看看运行时间:
runStep: step duration: 3 ms
runStep: step duration: 4 ms
runStep: step duration: 3 ms
runStep: step duration: 3 ms
runStep: step duration: 3 ms
runStep: step duration: 4 ms
runStep: step duration: 3 ms
runStep: step duration: 3 ms
runStep: step duration: 3 ms
runStep: step duration: 3 ms
runStep: step duration: 4 ms
runStep: step duration: 3 ms
runStep: step duration: 3 ms
runStep: step duration: 3 ms
runStep: step duration: 3 ms
runStep: step duration: 3 ms
runStep: step duration: 3 ms
runStep: step duration: 3 ms
runStep: step duration: 3 ms
Oh! 我的天哪!居然只要 3ms !!!
至此,优化计算速度全部完成!
总结
前期在写这个 APP 的时候,由于考虑到后续可能会有扩展,所以将原本只有两种情况的细胞状态使用了两个类来表示,使得遍历计算新状态的速度被大大降低。
其实想想也完全没有必要创建两个类来表示细胞状态,直接使用基本数据类型 Int 完全够用了,即使后续还有其他的状态也是够用的。
而除了创建对象导致耗时增加外,还有一个问题也是耗时大头,那就是我重复调用了很多次返回值明明是一致的方法,导致资源的浪费。
在数据量不大的情况下,可能压根看不出来,但是如果数据量一上来之后,这些耗时日积月累就会变得无法接受。
这启示了我,不要因为程序现在能跑就不管不顾代码是否合理,还是得该优化得优化。
最后,不得不说,C/C++ 不愧是编程语言的老大,运行速度是真的顶!